Machine Learning Research
Advanced machine learning methods for structure detection, time-series analysis, and multi-modal data integration are topics of current research interest. We focus especially on:
Multi-modal learning

Multiple data types naturally co-occur in medical practice. For example, medical data is often comprised of lab measurements, medical reports, and medical images. Learning from multiple data types is a long-standing goal in multimodal machine learning. In our research on multimodal learning, we aim to learn representations in a weakly-supervised manner, integrate information from complementary modalities, reduce uncertainty and ambiguity in redundant sources, and handle missing modalities.
We are especially interested in generative models and self-supervised approaches to learning meaningful representations. More concretely, we apply multimodal learning to leverage multiple views in echocardiograms, combined PET-CT modalities, and X-ray images and corresponding reports.
Clustering
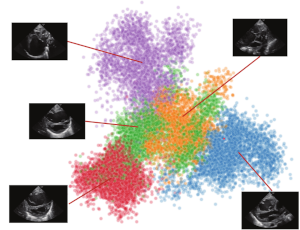
The ever-growing amount of data and the time cost associated with its labeling has made unsupervised learning a crucial task in the field of machine learning. Among various unsupervised learning techniques, clustering is the process of discovering groups of related objects. A typical biological application is subtype detection for tumor samples, where clusters containing mutually similar samples are associated with tumor subtypes. In our research, we are interested in integrating Bayesian clustering methods in the framework of deep generative models to achieve better representations of high-dimensional data. Deep generative models are highly intuitive and interpretable as they can naturally express causal relations of the world in the generative process of the data. However, there are many circumstances where purely data-driven approaches might lead to unsatisfactory results. The most common scenario is that not enough data is available to train well-performing and sufficiently generalized models. In medicine, for example, the learning process could be driven by unwanted bias, such as the type of machine used to record the data, rather than more informative features. Hence, we are interested in defining principled methods to integrate weak forms of supervision, given by the domain knowledge, into the clustering objective. In our research, we explored the integration of pairwise constraints, probabilistic relations, or general side information such as the survival time.
Interpretable and Explainable ML
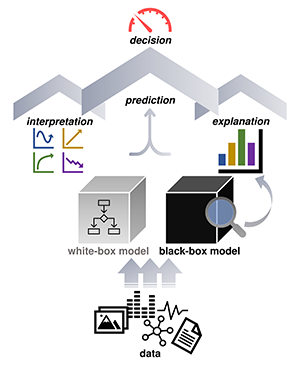
Interpretable and explainable machine learning study the design of human-understandable models (so-called, white-, glass-, or grey-boxes) and algorithms that allow for black-box model introspection after training, i.e. post hoc. In our research, we seek to understand what types of interpretations or explanations can be helpful in different facets of healthcare, e.g. clinical decision-making, predictive modelling, or biomedical scientific discovery. In practice, biomedical applications require developing novel techniques specific to the context, namely, to the considered data types and research questions to be answered. One line of our research focuses on interpretable neural network models, for instance, tailored towards understanding nonlinear time series dynamics or the exploratory analysis and subgroup discovery in unstructured survival data. We are also interested in translating interpretable and explainable ML to the actual practice. Our past projects in this direction include exploring high-dimensional nonlinear correlations among cerebral and peripheral bio-signals and learning data-driven medical risk scores for the management of pediatric patients with suspected appendicitis. More generally, we believe that interpretable and explainable ML will become part of the daily ‘tool set’ of a data scientist working in a high-stakes decision area. However, before the widespread adoption, together with specialists, we need to elucidate what interpretability and explainability mean for healthcare applications?
Longitudinal data analysis

Often, data is obtained at different points in time and dynamic models that take a time component into account are needed. For example in a medical setting, patients often visit a hospital multiple times, or stay in a hospital over a period of time. This results in time-stamped data for every patient. Depending on the disease, this might result in very long time-series data, with irregular time intervals, and many missing values. These are difficult challenges which require new machine learning methods for the efficient analysis of large amounts of longitudinal multi-modal clinical data, with the goal of gaining insights and making predictions about disease phenotypes, disease progression and response to treatment. A slightly different analysis goal might be to obtain a smooth clustering over all time points, sometimes called evolutionary clustering or dynamic clustering.